За последнее десятилетие глубокие нейронные сети достигли очень многообещающих результатов в различных задачах, включая задачи распознавания изображений. Несмотря на свои преимущества, эти сети очень сложны и сложны, что делает интерпретацию того, что они узнали, и определение процессов, лежащих в основе их предсказаний, трудными, а иногда и невозможными. Это отсутствие интерпретируемости делает глубокие нейронные сети несколько ненадежными.
Исследователи из Лаборатории анализа предсказаний Университета Дьюка под руководством профессора Синтии Рудин недавно разработали метод, который может улучшить интерпретируемость глубоких нейронных сетей. Этот подход, получивший название concept whitening (CW), был впервые представлен в статье, опубликованной в журнале Nature Machine Intelligence.
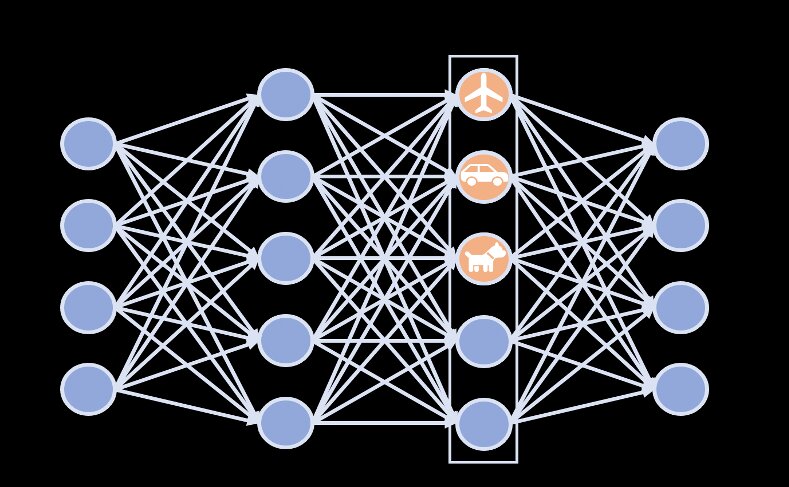
"Вместо того, чтобы проводить ретроспективный анализ, чтобы увидеть внутри слоя ННС, мы напрямую изменять НН расхлебывать скрытое пространство так, что оси совпадают с известными понятиями," Чжи Чэн, один из исследователей, кто проводил исследование, сказал Tech приложение. "Такое распутывание может дать нам гораздо более четкое понимание того, как сеть постепенно изучает концепции на разных уровнях. Он также фокусирует всю информацию об одном понятии (например," лампа"," кровать "или" человек"), чтобы пройти только через один нейрон; это то, что подразумевается под распутыванием."
Первоначально метод, разработанный Рудиным и ее коллегами, распутывает латентное пространство нейронной сети таким образом, что ее оси совпадают с известными понятиями. По сути, он выполняет "отбеливающее преобразование", которое напоминает способ преобразования сигнала в белый шум. Эта трансформация декоррелирует скрытое пространство. Впоследствии матрица вращения стратегически соответствует различным концепциям осей, не меняя эту декорреляцию.
"CW может быть применен к любому слою NN, чтобы получить интерпретируемость без ущерба для прогнозных характеристик модели", - объяснил Рудин. "В этом смысле мы достигаем интерпретируемости с очень небольшим усилием, и мы не теряем точность над Черным Ящиком."
Новый подход может быть использован для повышения интерпретируемости глубоких нейронных сетей для распознавания изображений без влияния на их производительность и точность. Кроме того, он не требует больших вычислительных мощностей, что облегчает его реализацию в различных моделях и использование более широкого спектра устройств.
"Глядя вдоль осей на более ранние слои сети, мы также можем видеть, как она создает абстракции понятий", - сказал Чэнь. "Например, во втором слое самолет выглядит как серый объект на синем фоне (который интересно может включать изображения морских существ). Нейронные сети не обладают большой выразительной силой только во втором слое, поэтому интересно понять, как они выражают такое сложное понятие, как "самолет" в этом слое."
Эта концепция может вскоре позволить исследователям в области глубокого обучения выполнять поиск неисправностей на моделях, которые они разрабатывают, и лучше понимать, можно ли доверять процессам, лежащим в основе предсказаний модели, или нет. Кроме того, повышение интерпретируемости глубоких нейронных сетей может помочь выявить возможные проблемы с обучающими наборами данных, что позволит разработчикам устранить эти проблемы и еще больше повысить надежность модели.
"В будущем, вместо того чтобы полагаться на предопределенные концепции, мы планируем обнаружить концепции из набора данных, особенно полезные неопределенные концепции, которые еще предстоит обнаружить", - добавил Чэнь. "Это позволило бы нам явным образом представить эти открытые концепции в скрытом пространстве нейронных сетей, распутанным образом, чтобы повысить интерпретируемость." | |
| Просмотров: 392 | |