Прошлые исследования неизменно подчеркивали решающую роль дофаминовых нейронов в обучении вознаграждению. Обучение вознаграждению-это процесс, посредством которого люди и другие животные приобретают различную информацию, навыки или поведение, получая вознаграждение после выполнения определенных действий или после предоставления "правильного" /желаемого ответа на вопрос.
Когда люди получают вознаграждение, которое лучше того, что они ожидают получить, дофаминовые нейроны активируются. И наоборот, когда вознаграждение, которое они получают, хуже, чем они предсказывали, дофаминовые нейроны подавляются. Этот специфический паттерн деятельности напоминает то, что известно как "ошибки предсказания вознаграждения", которые по существу являются различиями между полученными вознаграждениями и предсказанными.
Исследователи из Питтсбургского университета недавно провели исследование, изучающее, как частота вознаграждений и ошибок предсказания вознаграждения могут влиять на сигналы дофамина. Их статья, опубликованная в журнале Nature Neuroscience, дает новое и ценное представление о связанных с дофамином нейронных основах обучения вознаграждению.
"Ошибки предсказания вознаграждения имеют решающее значение для обучения животных и машин", - сказал доктор философии Уильям Р. Стаффер, один из исследователей, проводивших это исследование, в интервью Medical Xpress. - Однако в классических теориях обучения животных и машин "предсказанная награда" - это просто среднее значение прошлых результатов. Хотя эти прогнозы полезны, гораздо полезнее было бы предсказывать средние значения, а также более сложные статистические данные, отражающие неопределенность."
Исследователи черпали вдохновение в исследовании, опубликованном в 2005 году Вольфрамом Шульцем, главным научным сотрудником Wellcome, профессором нейробиологии Кембриджского университета и постдокторским наставником Штауффера. Это исследование 2005 года показало, что ответы на ошибки предсказания дофаминового вознаграждения нормализуются в соответствии со стандартными отклонениями, которые Шульц и его коллеги операционализировали как диапазоны между наибольшими и наименьшими исходами.
"Это исследование было новаторским, потому что оно показало, что нейронные предсказания действительно отражают неопределенность, - сказал Стаффер. - Однако существует несколько различных способов модуляции неопределенности, и я подозреваю, что они не являются психологически эквивалентными."
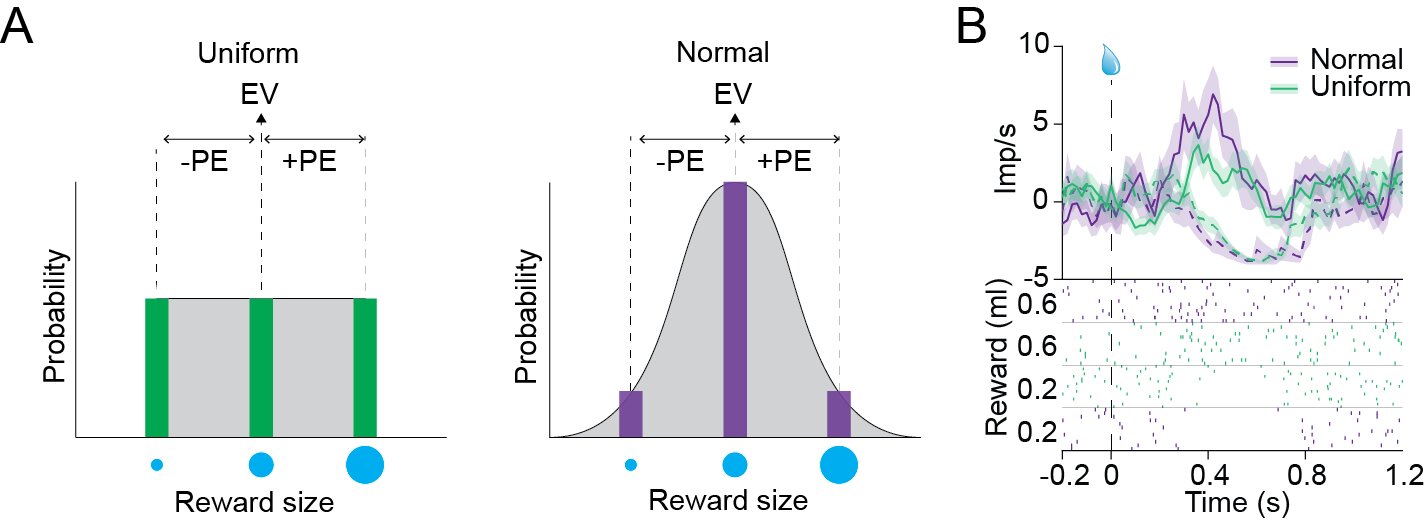
Модуляция диапазона, которую Шульц и его коллеги использовали в своем исследовании (для изменения стандартного отклонения), оставляла каждую потенциальную награду с той же предсказанной вероятностью.
"Нам было любопытно узнать, как будут реагировать дофаминовые нейроны, если диапазон будет постоянным, но относительная вероятность вознаграждения в этом диапазоне изменилась", - сказал Стаффер. "Соответственно, основной целью нашего исследования было выяснить, чувствительны ли дофаминовые нейроны к формам вероятностных распределений."
В своих экспериментах Стаффер и его коллеги использовали два различных визуальных сигнала для предсказания вознаграждений, полученных из двух различных "вероятностных распределений вознаграждений".
Одно из распределений вероятностей вознаграждения, однако, напоминало нормальное распределение, где центральное значение (т. Е. Средние капли сока) доставлялось в большинстве испытаний, в то время как маленькие и большие капли сока доставлялись редко. Второе распределение вероятностей вознаграждения, с другой стороны, следует за тем, что известно как "равномерное распределение", где малые, средние и большие вознаграждения были доставлены с равной вероятностью (то есть одинаковое количество раз).
Используя электроды, Стаффер и его коллеги записывали дофаминовые реакции, в то время как обезьяны просматривали визуальные сигналы, связанные с вознаграждением, из двух различных распределений вероятностей вознаграждения. Они также регистрировали дофаминовые реакции, когда обезьяны получали награды, "нарисованные" из распределений вероятностей виртуальных вознаграждений.
Примечательно, что исследователи заметили, что награды, которые вводились с более низкой частотой (то есть редкие награды), усиливали дофаминовые реакции в мозге обезьян. Для сравнения, награды точно такого же размера, но доставляемые с большей частотой, вызывали более слабые дофаминовые реакции.
"Наши наблюдения показывают, что предсказательные нейронные сигналы отражают уровень неопределенности, связанный с предсказаниями, а не только с предсказанными значениями", - сказал Стаффер. "Это также означает, что одна из основных систем обучения вознаграждению в мозге может оценивать неопределенность и потенциально обучать нижестоящие структуры мозга этой неопределенности. Есть несколько других нейронных систем, где мы имеем такие прямые доказательства алгоритмической природы нейронных реакций, и эти удивительные результаты указывают на новый аспект этого нейронного алгоритма."
Исследование, проведенное этой группой исследователей, подчеркивает влияние частоты вознаграждения на дофаминовые реакции, возникающие во время обучения вознаграждению. Эти результаты послужат основой для дальнейших исследований, которые могут значительно улучшить современное понимание нейронных механизмов, участвующих в обучении вознаграждению.
В конечном счете, исследователи хотят исследовать, как убеждения о вероятности могут быть применены к выбору, сделанному в условиях неопределенности (то есть, когда вероятности исхода неизвестны). В этих конкретных сценариях принятия решений люди, как правило, вынуждены принимать решения, основанные на их представлениях о распределении вероятностей вознаграждения.
"Это исследование стало первым шагом к пониманию того, как субъективные распределения вероятностей вознаграждения кодируются в мозге и какую форму могут принимать эти убеждения", - сказал Стаффер. "С этими результатами мы теперь вернемся к изучению выбора. Тем не менее, я подозреваю, что эти результаты будут иметь более широкие последствия, а также будут важны для систем обучения на основе биологического и искусственного интеллекта."
| |
| Просмотров: 556 | |