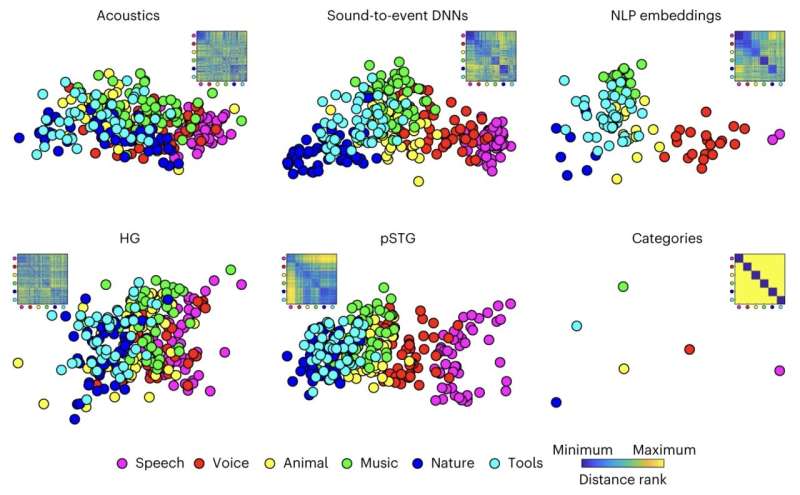
В последние годы методы машинного обучения ускорили и обновили исследования во многих областях, включая неврологию. Выявляя закономерности в экспериментальных данных, эти модели могут, например, предсказать нейронные процессы, связанные с конкретным опытом или обработкой сенсорных стимулов. Исследователи из CNRS, Университета Экс-Марсель и Маастрихтского университета недавно попытались с помощью вычислительных моделей предсказать, как человеческий мозг преобразует звуки в семантические представления о том, что происходит в окружающей среде. Их работа, опубликованная в журнале Nature Neuroscience, показывает, что некоторые модели на основе глубоких нейронных сетей (ГНС) могут лучше предсказывать нейронные процессы на основе данных нейровизуализации и экспериментальных данных.
"Наш основной интерес заключается в том, чтобы сделать численные предсказания о том, как естественные звуки воспринимаются и представляются в мозге, и использовать вычислительные модели для понимания того, как мы преобразуем услышанный акустический сигнал в семантическое представление объектов и событий в слуховой среде", - сказал Medical Xpress Бруно Джордано, один из исследователей, проводивших исследование. "Одним из главных препятствий на этом пути является не отсутствие вычислительных моделей - новые модели публикуются регулярно - а отсутствие систематических сравнений их способности учитывать поведенческие или нейровизуализационные данные". Основной целью недавней работы Джордано и его коллег было систематическое сравнение эффективности различных вычислительных моделей в предсказании нейронных представлений естественных звуков. В своих экспериментах команда оценивала три класса вычислительных моделей, а именно акустические, семантические и звукособытийные ДНК. "Мы начали говорить о необходимости проведения систематического сравнения вычислительных моделей в первые месяцы пандемии COVID", - объяснил Джордано. "После нескольких удаленных мозговых штурмов мы поняли, что у нас уже есть данные, необходимые для ответа на наш вопрос: поведенческий набор данных, собранный в 2009 году с 20 канадскими участниками, которые оценивали воспринимаемую несхожесть набора из 80 естественных звуков, и фМРТ-данные, собранные в 2016 году с пятью голландскими участниками, которые слышали другой набор из 288 естественных звуков, а мы записывали их фМРТ-ответы". Не собирая новых данных в лаборатории, исследователи решили проверить эффективность трех выбранных ими подходов к вычислительному моделированию, используя данные, собранные в предыдущих экспериментах. В частности, они отобразили звуковые стимулы, которые были предъявлены участникам эксперимента, на различные вычислительные модели, а затем измерили степень, в которой они могли предсказать, как участники реагировали на стимулы и что происходило в их мозге. Мы были ошеломлены тем, насколько ДНК "звук-событие", недавно разработанные компанией Google, превзошли конкурирующие акустические и семантические модели", - сказал Джордано. "Они настолько хорошо предсказывали наши поведенческие и фМРТ-данные, что, сопоставив звуки с ДНК, мы могли предсказать поведение наших канадских участников 2009 года по фМРТ-ответам голландских участников 2016 года, даже если звуки, которые они слышали, были совершенно другими". Джордано и его коллеги обнаружили, что модели на основе ДНК значительно превосходят как вычислительные подходы, основанные на акустике, так и методы, характеризующие реакцию мозга на звуки путем отнесения их к различным категориям (например, голоса, уличные звуки и т.д.). По сравнению с этими более традиционными вычислительными подходами, ДНК могли предсказывать нейронную активность и поведение участников со значительно большей точностью. На основании своих наблюдений и результатов, полученных с помощью моделей на основе ДНК, исследователи также предположили, что человеческий мозг воспринимает естественные звуки аналогично тому, как он воспринимает слова. В то время как смысл слов определяется путем обработки отдельных букв, фраз и слогов, смысл звуков может быть извлечен путем комбинирования другого набора элементарных единиц. "Сейчас мы работаем над сбором новых нейровизуализационных данных для проверки конкретных гипотез, выдвинутых в нашем исследовании, о том, какими могут быть эти элементарные единицы", - добавила Элиа Формизано. "Мы также работаем над обучением новых и более "мозгоподобных" нейронных сетей для обработки естественных звуков. Например, наш соавтор, Микеле Эспозито, разработал нейронную сеть, которая обучается числовым представлениям вербальных звуковых дескрипторов (семантическим вкраплениям), а не категориям звуковых событий. Эта сеть, которая будет представлена на Международной конференции по акустике, речи и обработке сигналов (ICASSP) 2023, превосходит сети Google в предсказании восприятия естественных звуков". | |
| Просмотров: 180 | |